The Hitchhiker's Guide to Agent Evals

Evaluations line the road to Software 2.0. They serve a critical role in everything from model training to application development. Agent architecture is the latest pattern to emerge in the rapidly evolving frontier of AI applications, and evaluating agents deserves special attention.
Compared to their more deterministic predecessors, agents think more. In other words, they process more logic through the model than through explicitly written application code. They loop through workflows, deciding which tools (functions) to call and what to do next.
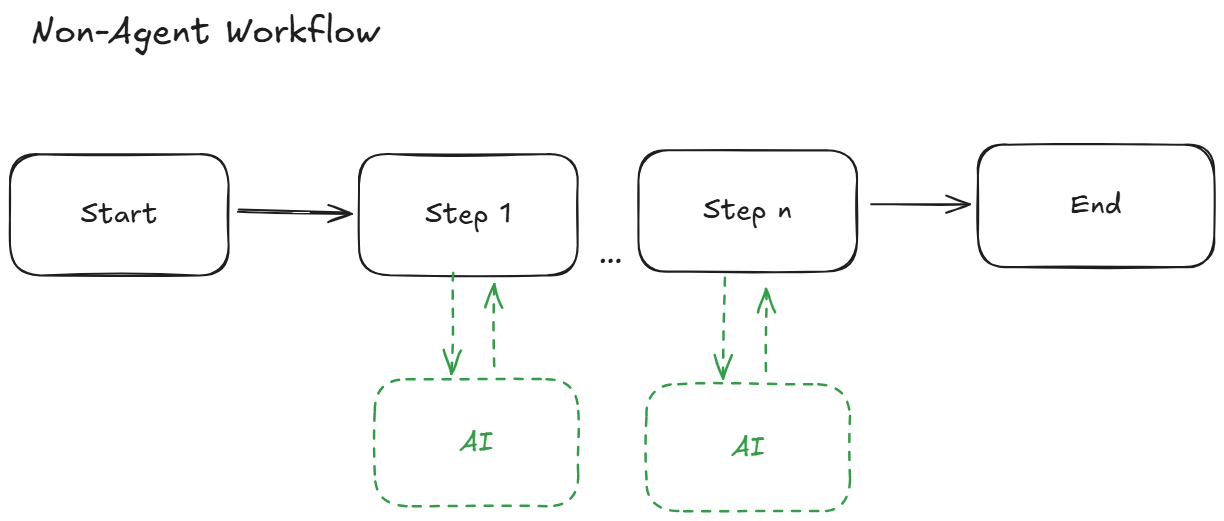 Invokes model as needed
Invokes model as needed
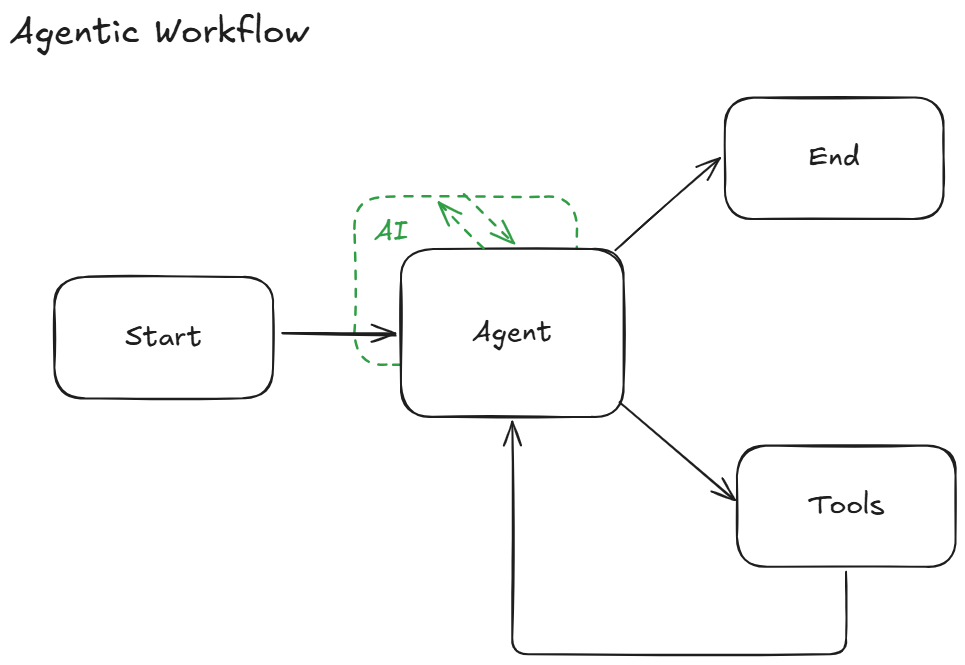 Invokes model as the central orchestrator
Invokes model as the central orchestrator
Evaluating Agents
We evaluate agents by observing how they execute workflows. I highly recommend LangChain's overview for more about this concept. Basically, an agent's entire execution thread is traceable. Thus, you can set up tests to verify agent behavior at different levels of scrutiny.
-
Final Output - evaluate the final output
-
Single Step - evaluate a single step in the execution
-
Trajectory - evaluate the order of steps in the execution
In Practice
Every agent application has different objectives and tolerance for variable behavior. To set up effective evaluations, identify the critical behaviors that your agent needs to perform and create evaluations tailored to your expectations.
I recently built a fitness companion agent called CoachAI.
The agent builds personalized programs and provides real-time coaching to users during workouts. It has access to tools for managing application state and long-term data storage.
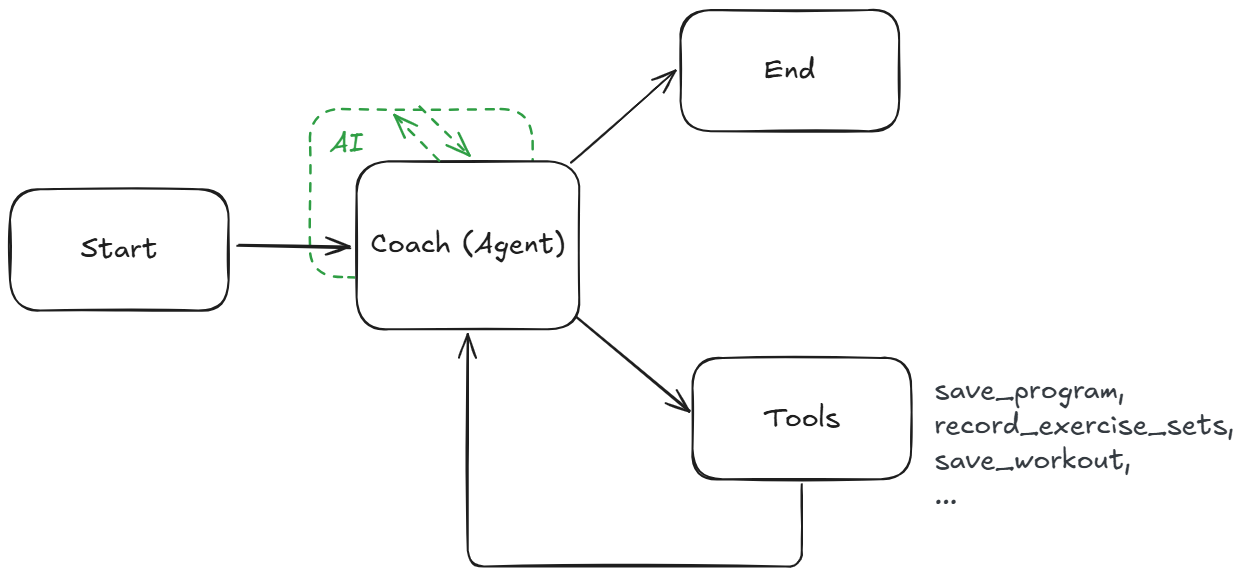
One critical behavior is to reliably record user reported data during workouts. To accomplish this, the agent accurately interprets the user's message, uses the record_exercise_sets tool successfully, and communicates back to the user appropriately.
To confirm that the agent does this, I created two types of evaluations.
-
Final Output - Ensure the agent communicates appropriately
-
Single Step - Ensure the agent uses
record_exercise_setssuccessfully
I decided not to include trajectory evaluations because I don't need to monitor efficiency. However, use cases with a premium on efficiency or sensitive orders of operation benefit from such evaluations.
To implement the evaluations,
-
Capture the scenario
-
Create datasets
-
Define evaluator logic
I used LangGraph SDK for my evaluation framework. In this post, I avoid framework-specific details as much as possible.
Capture the scenario
To evaluate an agent's behavior, capture the scenario in which you expect the behavior to occur.
This is challenging with agents because they involve multi-turn interactions. For example, users of CoachAI do not immediately begin reporting data for workout session. Conversations are nondeterministic so every user takes a different path to the scenario that I want to evaluate.
One way to overcome this is to time-travel to the scenario with a static, mocked application state. The approach is simple: define an application state one turn prior to when users commonly report their set information during an active workout. The agent application instantiates with this state and immediately hits the scenario when the evaluations run.
For my agent, I defined a JSON object that mimics the application state exactly one turn prior to when users commonly report their set information during an active workout. See code snippet here.
More comprehensive approaches exist. See simulating multi-turn conversations and evaluating traces from live environments.
Create datasets
The datasets describe input/output pairs of expected behavior for the agent. Often referred to as the "Golden Dataset", they provide examples of ideal behavior that your agent will be benchmarked against.
For my agent, I have datasets for both the final output and single step evaluations. The final output dataset contains sets of user inputs with expected agent responses.
Ex.
{
"input": "Set 1 10 reps 135lbs",`
"expected": "Great work! Let's move on to set 2."`
}
The single step dataset contains sets of user inputs with the expected value of a variable tracking successful tool calls.
Ex.
{
"input": "Set 1 10 reps 135 lbs",
"expected": "record_exercise_sets_called"
}
Define evaluator logic
Last but not least, write the evaluator logic. It compares the action of the agent with the examples from your datasets to generate a score. I find binary pass/fail scores to be most practical.
My final output evaluator uses LLM-as-a-judge method to determine whether the agent's response is similar to my example. See a code snippet here.
My single step evaluator inspects the tool calls and responses from the agent's actions. It checks for at least one successful call. See a code snippet here.
All together now
My evaluation framework spins up an instance of the agent with the mocked application state, runs it with the evaluation datasets, and scores the agent based on the evaluator logic.
With these pieces in place, I have evaluations that ensure the agent is behaving as expected when users report data during workouts. When developing new features or updating the application, this is indispensable.
Thank you for reading.