March madness tracker experiment
I built a personalized march madness tracker. It allows me to quickly view my matchups when competing in large and complex NCAA tournament bracket pools that are managed in spreadsheets. It automatically updates throughout the tournament.
My goal was to spin up a solution as quickly as possible, minimize dev effort, and play around with the latest agentic tools. Here's how it works and what I learned.
How it works
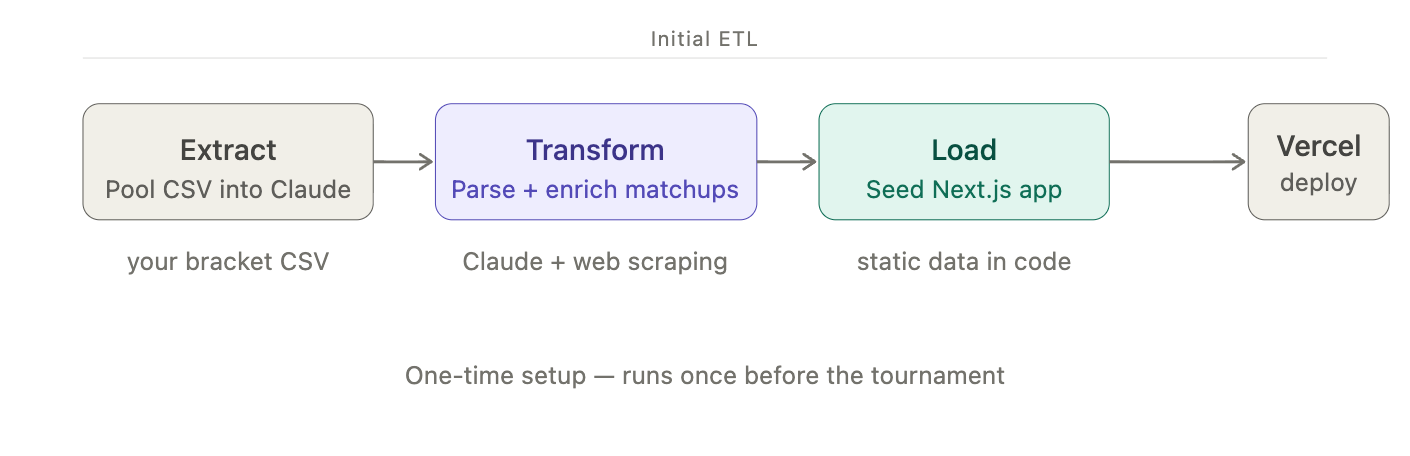
Initial ETL
In order to pull the matchups relevant to me, I executed a simple ETL process, leaning heavily on mainstream agent solutions.
- Dropped the pool CSV into Claude
- Extracted matchups relevant to me
- Transformed the data into a simple list
- Scraped the web for game times and broadcast networks
- Sorted the matchups by tipoff time
- Spun up a simple nextjs app to store the list and display my matchups
- Initially, I only planned to store an image on my phone. However, when I asked Claude to generate an image of a nice view of the data, it did so by building a website and using Playwright to take a screenshot. Figuring I was already halfway there, I decided to make it a fully dynamic site. I asked Claude for the source code. Then, I dropped it into Vercel's v0 to generate a nextjs app.
- Deployed to Vercel with a public domain madness-tracker.vercel.app
I now had a view that I could access on any device with an internet connection and personalized matchup data stored in a file with my app code.
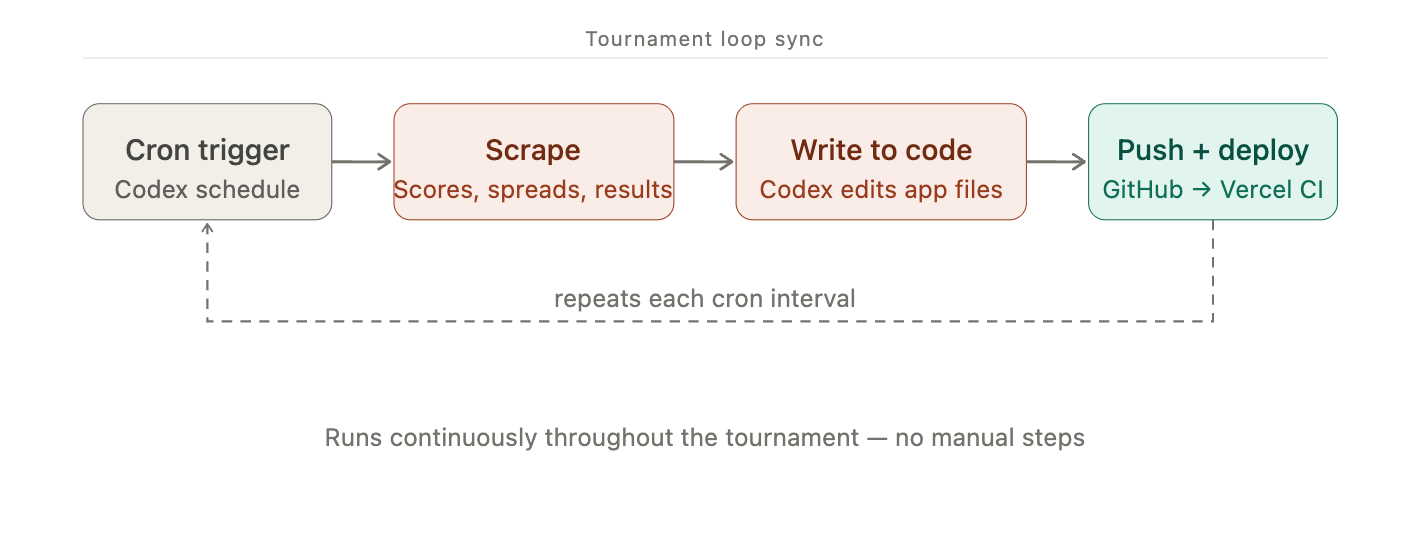
Regular Sync
In order to update the view throughout the tournament, I set up Codex Automations (cron jobs that trigger agents) to scrape spreads, scores, and results throughout the tournament. I set it up with gpt-5.4-mini and low reasoning.
Here's the prompt I used for the score sync automation.
Find the matchups list in page.tsx.
For each matchup record find the current score values published by ESPN on their live scoreboard webpage at https://www.espn.com/mens-college-basketball/scoreboard.
Update the "myScore" and "theirScore" values to the current scores.
Commit the change on main with message "Sync scores with ESPN" and push to remote.
The agent updates the data stored in the nextjs app by editing the file directly and pushing the changes to github. Vercel's GitHub integration listens for the changes and deploys the new version to prod.
I scheduled my cron job to fire every hour during the first two rounds of the tournament and then daily for the later rounds. The agent workflow takes roughly 1 minute. The deployment takes 15-20s.
Findings
- Time to build = 1 hour
- Total cost = $1.26
Because the consumer-facing agent solutions that I used do not surface exact telemetry data (unlike their API and developer services) and costs are muddied by subscription bundles across products, exact cost for this project was impossible to determine. Here's how I estimated it.
Build cost = $0.18
My usage for the ETL process was covered by my standard subscription plans. Assuming I use these products 8 hours per day,
8 hours per day * 7 days per week * 4 weeks per month = 224 hours per month
This project took 1 hour to build, so
(1/224) * $40 per month = $0.1786
| Product | Plan | Price |
|---|---|---|
| Anthropic's Claude | Pro | $20 per month |
| OpenAI's Codex | ChatGPT Plus | $20 per month |
| Vercel's v0 | Free | Free |
Hosting, CI/CD cost = $0.00
| Product | Plan | Price |
|---|---|---|
| GitHub | Free | Free |
| Vercel cloud | Free | Free |
Sync Cost = $1.08
Technically my Codex Automations costs are covered by my OpenAI ChatGPT Plus subscription, but I wanted to understand roughly how much the agent cron jobs would cost outside of a subscription.
I simulated the codex automations in OpenAI's dev dashboard to get a rough idea of the tokens used and hypothetical inference cost per sync. Here are the results.
| Token Type | Count | Cost per 1M tokens | Est. total cost per sync |
|---|---|---|---|
| Input | 23,548 | $0.75 | $0.0177 |
| Output | 1,285 | $4.50 | $0.0058 |
| Total | $0.0235 |
I then calculated how many syncs would run during the tournament to get the total sync cost.
Hourly syncs for the first 2 rounds
12 hours * 4 days = 48 syncs
Daily syncs thereafter
2 days for Sweet 16 + 2 days for Elite 8 + 1 day each for the Final Four and the Championship = 6 syncs
Total syncs during tournament`
48 + 6 = 54
Total cost for the syncs
54 syncs * $0.02 per sync = $1.08
Thoughts
Without these tools, this project could have easily taken 10x as long. Using agents across my data analysis, app development, integration design, and deployment workflows as well as embedding them into the solution itself enabled me to spin up a fully functional solution in 1 hour.
Personal software unlocks unconventional design decisions. Because I was building this app for myself, with a shelf life of only 3 weeks, and with readily available public data, I was able to make scrappy and pragmatic design decisions (data storage in file, agent cron jobs, no auth) that are not typical of a multitenant or risk-sensitive solution. Speed and accuracy were important here. Scalability and efficiency were not.
This project shows that software is poised to tackle a host of new problems: the long tail of hyperspecific personal problems that were once uneconomical to pursue and are now easy pickings.
The source code is available here